こんにちは。サービス開発部のshgxです。
GameWith アドベントカレンダー2024 5日目の記事です。
GameWithには、攻略ゲーム毎に記事を検索する機能があります。 今回はこの機能でリプレイスを実施した内容についてご紹介したいと思います。 リプレイス前のシステムの構築(2018年)についての記事もあるので、こちらも併せて御覧ください。
1. はじめに
最初に紹介した記事の通り2018年にGameWithの記事検索システムがリリースされました。 その後、初期構築を担当したエンジニアが退職してから長い間運用を主軸にメンテナンスが行われてきました。 その間今年(2024年)まで6年も安定的にシステムが稼働してきました。初期はiOSやAndroidのアプリ上の検索のみでしたが、WEB上のゲームの個別検索に導入されるなど導入面も増えて負荷が課題になったこと、 AIなどの新機能への対応・コストの削減も兼ねて、リプレイスを実行することにしました。
2. 旧システムの設計・概要
システム構成は以下の通りになります。
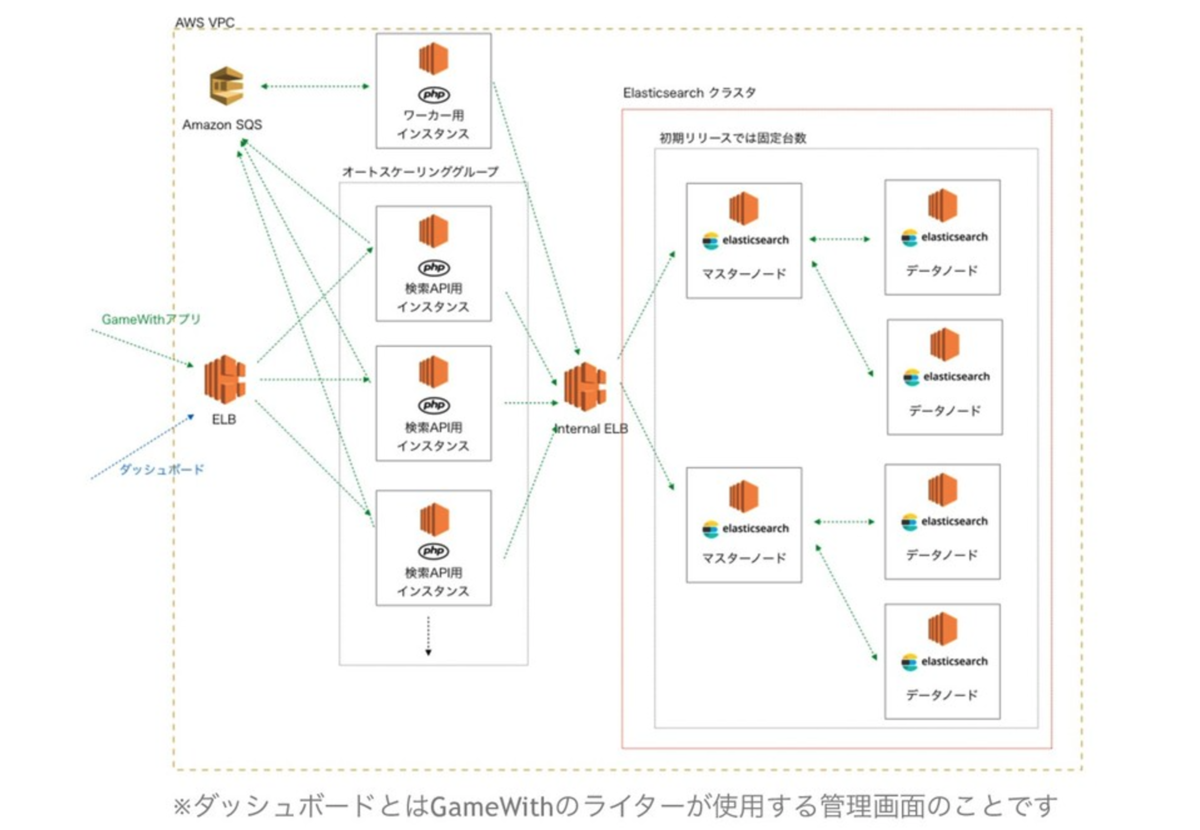
使用技術は基本的に全てPHPで書かれていて、 APIなどのバックエンド系はlaravelで実装されておりました。 検索のクラスタが2つと非常に冗長性の高いシステムになっておりますが、 当時の状況からかAPIも含めて全てがEC2でデプロイされていることもあって基本固定のままで、 インスタンスの最適化や自動化もしづらく、運用のコストが全体の中では高めになっておりました。 また、高負荷時にエラーが起きる・検索速度の低下なども起こっていたため、システムの負荷も課題でした。
3. 新システムの設計・概要
システムの構成は以下の通りになります。
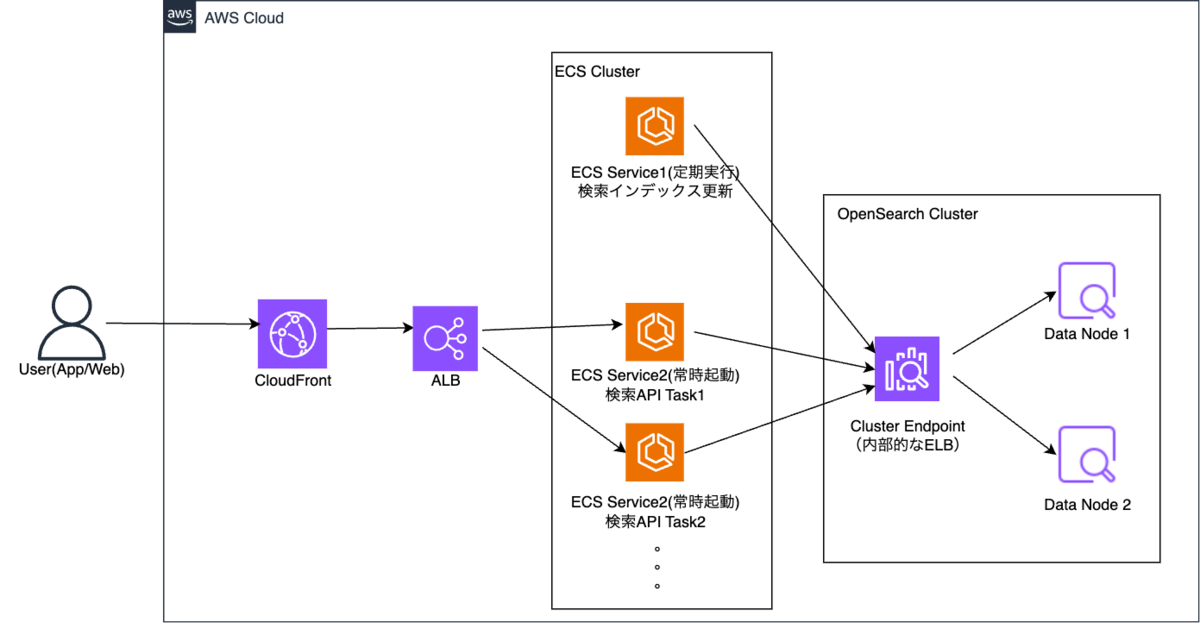
変更点は以下の感じです。
セルフマネージドの割合下げました
PHPベースからGoベースに変更
ElasticsearchからOpenSearchに移行
記事更新を定期実行に変更
使用言語について、現在の社内のAPIプロジェクトでの採用率が高いこと、社内で使える人が多くメンテナンスがしやすいこと、 マルチスレッド処理含め比較的高速で、見通しよくシンプルに実装できるためGo言語を採用しました。
実装のアーキテクチャはクリーンアーキテクチャ+ドメイン駆動で実装しました。 また、APIをECR/ECSを利用したコンテナベースでの管理に変更しました。 ECSのクラスターで管理しているので、CI利用した自動デプロイ・台数調整や環境変数の変更など圧倒的に管理がしやすくなります。
さらに、検索インフラをEC2ベースのElasticsearchからAWSのOpenSearchクラスタへ移行しました。 新機能で入れる予定のベクトル検索・機械学習周りの機能対応がOpensearchの方が十分に出来ていたことと、 検索クラスタの状態の管理がAWS側で一括管理できる(CloudWatchでモニタリングできる)ことも挙げられます。
SQSでのキューイングをやめた理由は主にベクトル検索などインデックス生成のコストや、処理の負荷を下げるためになります。 ベクトル検索のインデックスの作成にはその度に埋め込み表現を生成するコストがかかりますので、それを極力減らすためです。 また、軽微な更新で頻繁にインデックスの更新をするとフラグメントの発生を起こしやすくなり検索の劣化や速度低下を起こしてしまう危惧があるためです。 更新を定期実行にすることで、CDN側にキャッシュをもたせる余地が増えるという面もあります。

シンプルになりました!
4. 移行戦略
まずは、旧検索システムへのアクセスの経路、どういう使用状況かをエンドポイント毎でNotionにまとめていきました。 また、残されているドキュメントや実装コードから検索APIの詳しい仕様を理解していきました。 その後はアクセスが有るものを互換として残すことにして、残すエンドポイントを決定し、基礎的なアーキテクチャの設計を行いました。 昔のAPIと同等のレスポンスを返すapi/v1で実装しておき、新機能のAPIはapi/v2で実装する、という感じにしました。
そこから移行の戦略を立てて行きました。
課題としては、データ移行の方法・ダウンタイムの最小化・リスク管理がありました。
データ移行の方法については、ElasticsearchとOpenSearchは基本実装が同じなので、基本的に同構造のままデータの移行は出来るのですが、 記事データの保持の方法や負荷の課題、新機能への対応の観点から、基礎的な検索のロジックは維持しつつ新たにインデックスを再構築する方針にしました。
ダウンタイムの最小化については、エンドポイント自体はRoute53経由で同じにして、 重み付けルーティング (Weighted Routing) を利用してダウンタイムほぼ無しの状態での段階的に切り替えすることにしました。
以下のような感じで、新しいシステムがレコード2なら10ずつ増やしていってレコード1を10ずつ減らしていくイメージ
example.com |- レコード1: weight=70 → us-east-1のELB |- レコード2: weight=30 → us-west-2のELB
リスクの管理として、一定期間は安定稼働がある程度保証されている旧システムを維持しつつ徐々に新システムに切り替え、 数週間問題ないことを確認したうえで旧システムの削除等の処置を行うことに決めました。

重み付けルーティング便利!
5. 実装やシステム構築時のポイント
実装のポイント
検索時の負荷が旧システムでは課題になっていましたので、一旦はPHPの実装ベースからGoにそのまま元の通り移植してから、その実装の最適化を行いました。 実行時間の計測などをしてみて、特に2つのデータソース(elasticsearchとsqlなど)に交互で頻繁に問い合わせを行っており、 この構造が高負荷時のボトルネックになっていたため1つのデータソース(opensearch)だけを参照できるように検索の実装を変更することにしました。
検索インデックス設計
実装の変更や機能の追加にあたって、検索インデックスやその保持するデータの項目は増えることになります。 そのため、一応仮の負荷テストを行い項目が増えても検索の速度が明確に低下しないことを確認しました。
検索ロジックの変更と事業部側との調整
先程の実装のポイントで話した内容も含めて検索ロジックの改善を行いましたが、 結果として現在の結果と違うことになってしまったので、事業部側で検索結果をテスト確認してもらい、 理想の検索結果をもらったり、やり取りをしながら何度か調整しました。
マイグレーション
また、OpenSearchなど検索エンジン系は実装自体にmappingを載せることが多い印象ですが、それだとインデックスの管理がしづらくなるので、 将来の変更なども容易にできるようにするため、OpenSearchのインデックスのマイグレーションツールを自作しました。 ワンコマンドでjsonの定義ファイルからインデックスの構成の追加・更新など基礎的な操作ができるようになっています。reindexも対応出来るようにする予定です。
検索クラスタの構成・インスタンスの選定
また、検索インスタンスについて、コストの削減がリプレイスの目標としてはあったので、必要十分なおかつ多少余裕があるインスタンスを選ぶ必要がありました。 インデックスの設計や基礎的な検索の実装が終わった後、複数のインスタンスで負荷テストを行いました。 負荷テストは実際の高負荷時・平常時の秒間アクセス数を2~3倍したものをベースにしつつ行いました。
負荷テストのシナリオを以下のように分けました。
- 通常負荷テスト
- ピーク負荷テスト
- 段階的負荷増加テスト
- 高負荷&将来成長シミュレーションテスト
負荷はそれぞれのテストの最中や終わった後のOpenSearchのモニタリングをCloudWatchで確認しました。 主に負荷テスト時の応答速度、CPU負荷率とJVMメモリプレッシャーを見ていました。 OpenSearchにおいてJVMメモリプレッシャーが75%を超える場合ガベージコレクターが動くため、CPUに高負荷がかかり応答速度が遅くなる懸念があります。 そのため、JVMメモリプレッシャーが75%を超えない、CPU負荷75%を超えないということ基準で見ていました。応答速度は最大1秒以内に収まる、という基準。
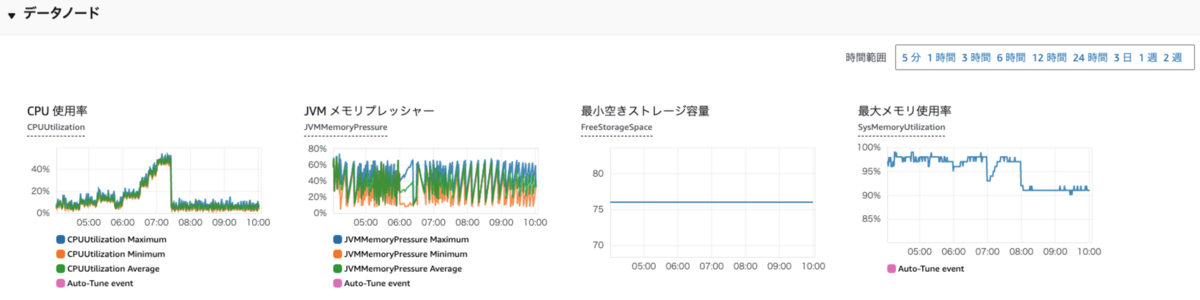
それぞれでテストした結果、本来は旧検索システムと同じようにマスターノードとデータノード2のクラスタ構成で行こうと思っていましたが、 検証の結果余裕がありすぎるということが分かったので、マスターノードは省くことにしました。 最終的にARMのデータノードを2台クラスタとして利用するようにしました。 APIのインスタンスも検索のクラスタの構成が決まった後、負荷テストを行いかなり余裕を持って基礎的な台数を決定しました。
インスタンスの最適化大事!
6. 結果と効果
実装もインフラの移行も問題なくダウンタイム無しで実施できました!1ヶ月前辺りから順調に稼働しています。
効果としては、検索の処理改善が功を奏し、基礎的な応答速度が約60分の1に改善。高負荷時にあたっては130分の1に改善しました! 定期更新・最適化などによってCloudFrontなどCDNキャッシュが広く効くようになったため、高負荷時の応答など数字以上の効果もありそうです。 検索時に明らかに速くなったためユーザーの体験としても良くなっていると思っています。事業部の方は喜んでました。
旧記事検索APIの応答時間
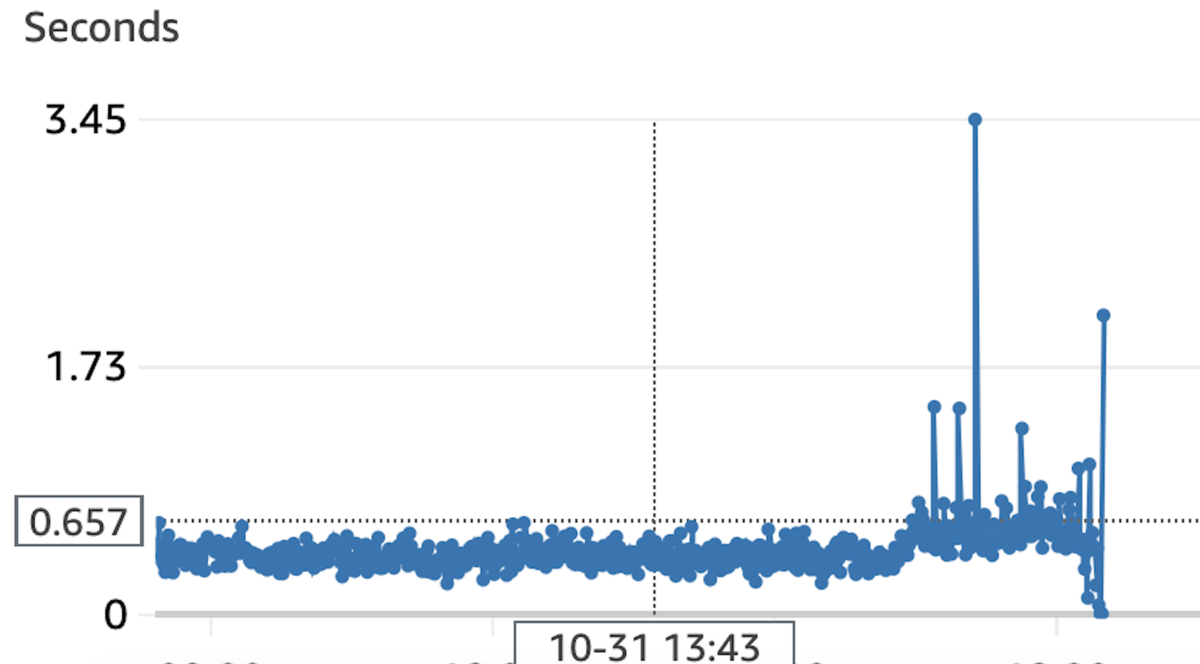
新記事検索APIの応答時間
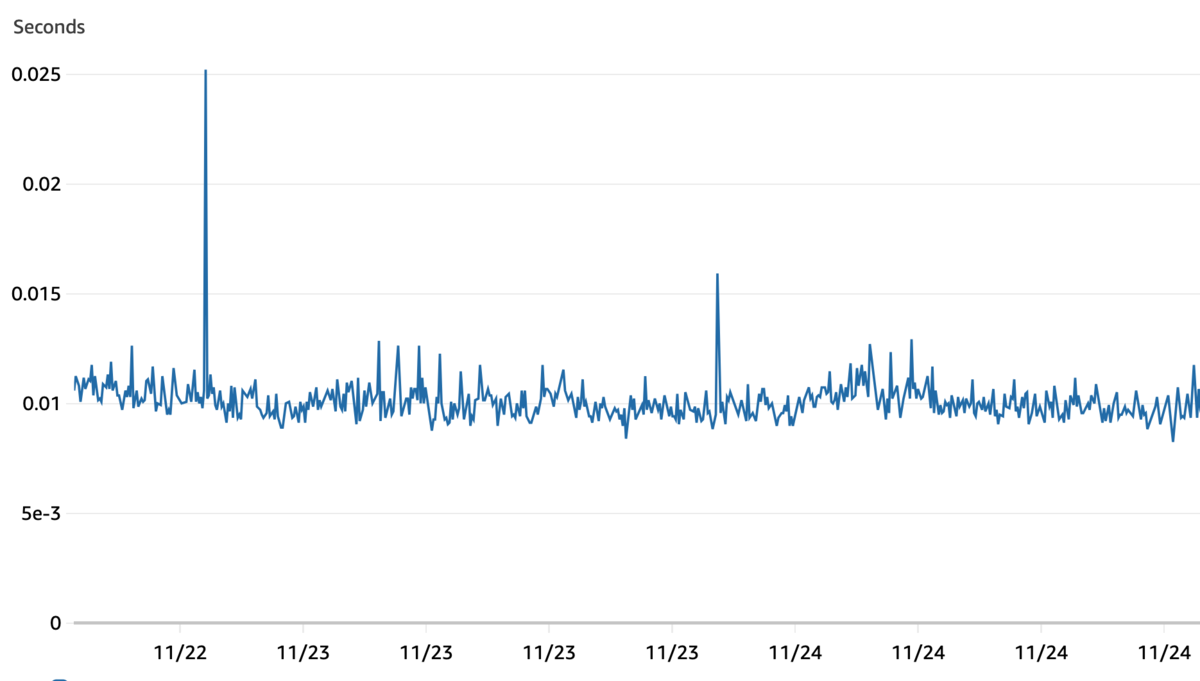
また、RIインスタンスの購入タイミングに乗れたこと、ARMインタンスへの置き換えたことなども含めて年換算では4500ドル程度(70万円程度)の費用削減にもなりました。 インフラを管理するコストも、コードを管理するコストも大幅に下がっていると考えています。 また、ベクトル検索、ひらがな・よみがな検索などの新機能追加、検索機能の向上も出来たため一石二鳥でした!
速くなったし、想定より多めにコストの削減ができて嬉しい!
7. 振り返りとまとめ
このリプレイスで一番大変だったことについてですが、検索結果の品質調整において多くの課題に直面したことがあります。 アルゴリズムや処理効率、ロジックの改善により理論上は検索精度が向上しているにもかかわらず、事業部門の期待する検索結果との間にギャップが生じることもありました。 理想的な検索結果例を複数個いただいてから、その一致度の具合で検索の調整をじっくり行った結果、最終的には納得いただける結果が出せました。 ビジネスの要件と技術的な最適解のバランスを取ることの難しさを再認識しました....あと、検索技術の奥深さも。
なぜこういう実装になったか、ロジックになったのか、こういうアーキテクチャになったのか、 実装やアークテクチャのプラクティスについて技術的な知見を深める貴重な機会でした。なかなか面白かったです!
既存の検索のリプレイスは終わりましたが、今度はそのシステムを利用しての新機能開発が待っています。 ユーザー側にも面白い機能が提供できるかもしれないので、こちらは引き続き頑張っていきたいと思います。
こんなGameWithではエンジニアを絶賛募集中です!
サーバーエンジニアやフロントエンジニアの方、AIに興味がある方や、Unityでの開発に興味がある方もお気軽にカジュアル面談をお申し込みください!