 GameWith エンジニアの @skagawa です。開発部の部長をしています。他には、騎空士、マスター、新人スタッフのお仕事もしています。
GameWith エンジニアの @skagawa です。開発部の部長をしています。他には、騎空士、マスター、新人スタッフのお仕事もしています。
GameWithでは「リリース通知」というゲームがリリースされたことをユーザーにメールとおしらせ通知で知らせるサービスを提供しています。
ゲームタイトルは日々発表されているため、ユーザーが自分好みのゲームを見つけることが難しくなっています。
その課題を解決するため、GameWithでは「ゲームレビュー」でのゲーム情報の発信とは別に、
- リリース通知対象タイトルのピックアップ
- 登録数ランキング
というユーザーが新しいゲームを見つけられるためのコンテンツを用意しています。
ピックアップされるゲームタイトルは多腕バンディット(アルゴリズムはThompson sampling)を活用し、
新しく発表されたゲームタイトルの露出機会を設けつつ、ピックアップ枠経由での登録が多いゲームタイトルが最適に表示されるようにしています。
今後はよりユーザーが興味のあるであろうゲームタイトルをおすすめできるよう、レコメンド形式でのゲームピックアップの検証を進めています。
まだ実際のサービスとはなっていませんが、今回は検証中の仕組みを使ったゲームレコメンドを紹介します。
実装概要
以下の2つの観点で抽出したゲームタイトルを統合して、ゲームレコメンドとして提供する
- 全ユーザがリリース通知登録したゲームを元に、協調フィルタリングでゲームを推薦
- ユーザの行動履歴(リリース通知登録、ゲームプロフィール登録、ゲーム紹介記事閲覧(今回の検証では含まない))を評価点と仮定し、ALSでゲームを推薦
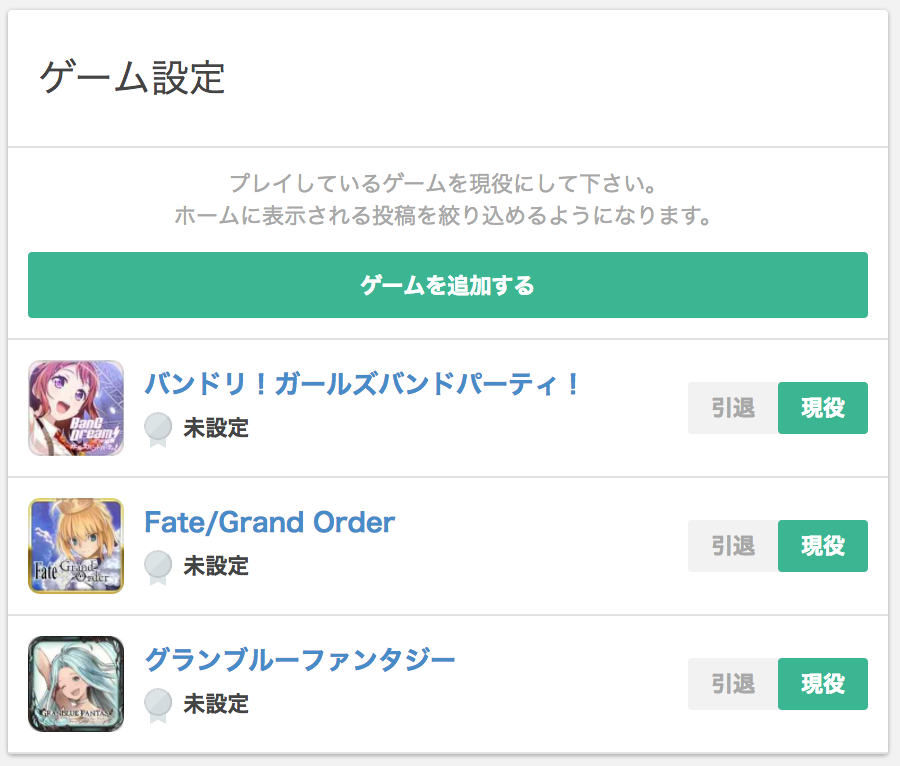
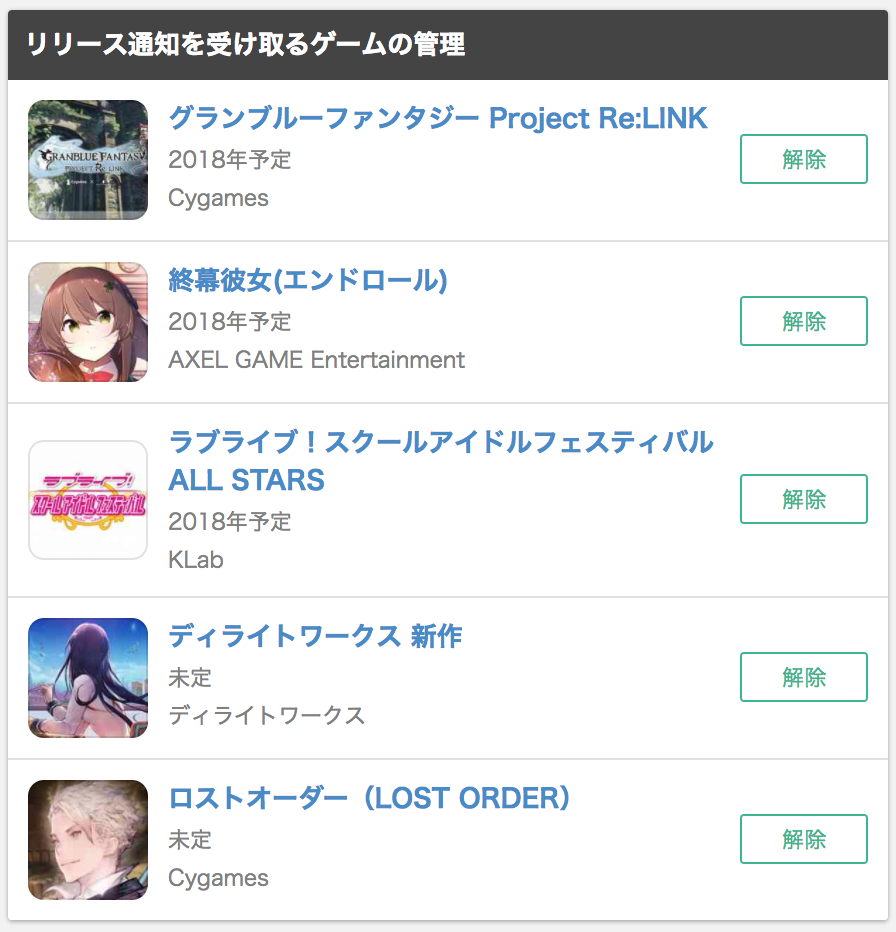
今回の検証対象ユーザー
GameWithで以下のゲームを登録しました
データのサンプル
協調フィルタリング用データ
... 889015 1218 889015 1219 889015 2174 889015 2372 889015 2460 ...
ALS用データ
... 889015 256 4 889015 22 4 889015 1266 4 889015 1218 2 889015 1219 2 889015 2174 2 889015 2372 2 889015 2460 2 ...
レコメンドデータの生成
今回は Amazon EMR を利用してデータを生成します。
協調フィルタリング(Mahoutのコマンド)
$ mahout itemsimilarity --input s3n://test-gamewith-recommend/input/xxxx.tsv --output s3n://test-gamewith-recommend/output/xxxx --tempDir /mnt/var/tmp/`date "+%Y%m%d%H%M%S%3N"` --maxSimilaritiesPerItem 10 --booleanData true --similarityClassname SIMILARITY_COOCCURRENCE
ALS(Spark Scalaのコード)
package jp.gamewith.recommend.als import org.apache.spark.SparkContext import org.apache.spark.SparkConf import org.apache.spark.mllib.recommendation.ALS import org.apache.spark.mllib.recommendation.Rating object Recommend { def main(args: Array[String]): Unit = { val awsKey = "xxxxx" val awsSecret = "xxxxx" val trainFile = "s3n://xxxx/xxxx.tsv" val predictFile = "s3n://xxxx/prediction" val productsFile = "s3n://xxxx/target.txt" val conf = new SparkConf() .setAppName("alsRecommend") .setMaster("local") .set("spark.eventLog.enabled", "false") .set("spark.local.dir", "/mnt/var/tmp") .set(...) // 省略 val sc = new SparkContext(conf) sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", awsKey) sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", awsSecret) val seeds = sc.textFile(trainFile) .filter(_.nonEmpty) .map(_.split("\t") match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble) }).cache val products = sc.textFile(productsFile) .filter(_.nonEmpty) .collect val rank = args.applyOrElse(0, (n: Int) => "10").toInt val numIterations = args.applyOrElse(1, (n: Int) => "10").toInt val alpha = args.applyOrElse(2, (n: Int) => "0.01").toDouble val lambda = args.applyOrElse(3, (n: Int) => "0.01").toDouble val model = ALS.trainImplicit(seeds, rank, numIterations, lambda, alpha) val usersProductsRdd = for { user <- seeds.map { case Rating(user, product, rate) => user }.distinct product <- products } yield (user, product.toInt) val predictions = model.predict(usersProductsRdd).map { case Rating(user, product, rate) => (user, product, rate) } filter { f: (Int, Int, Double) => 0.0 <= f._3 } predictions.saveAsTextFile(predictFile) sc.stop } }
※ Scala初心者なので最適なロジックではないですがご了承を...
レコメンドデータを取り込み、おすすめゲームを表示する
実サービスとしては提供していないため、弊社の管理画面上で該当ユーザーのおすすめゲームリストを確認できるようにしました。
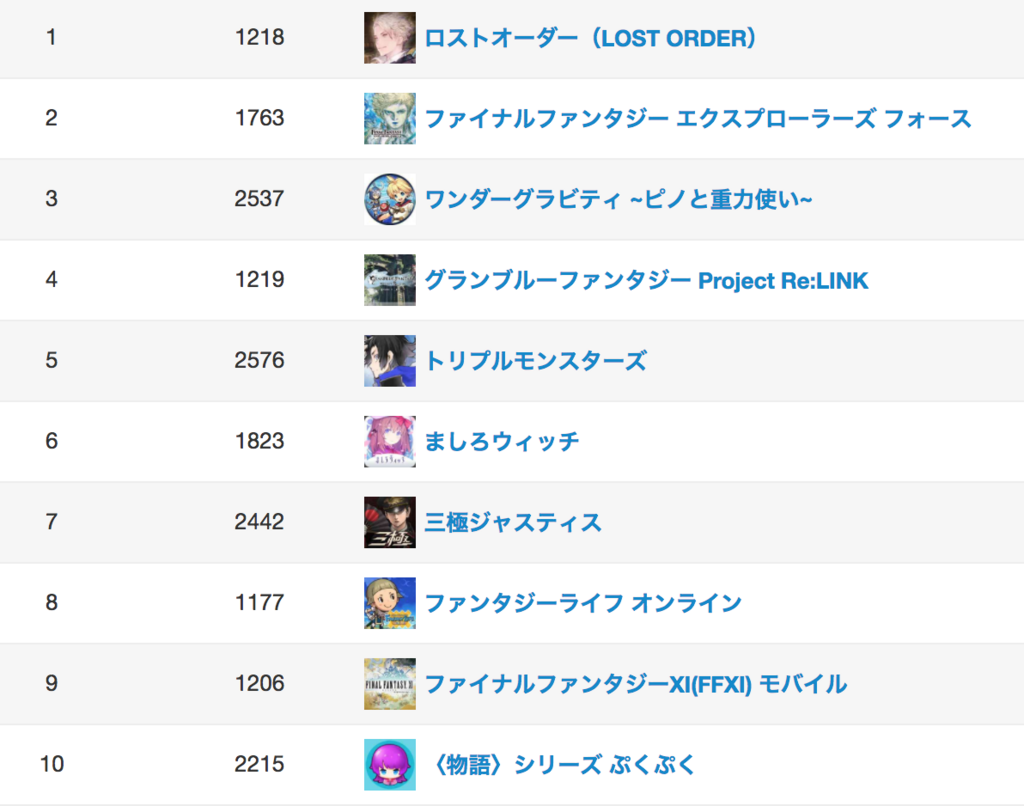 ※ 登録済みのゲームを除外しないといけないですね...
※ 登録済みのゲームを除外しないといけないですね...
いかがでしょうか?
FFXFとワンダーグラビティ辺りは興味が湧いたので、精度はそれなりにあるのかなと思います。
今後はパラメータやデータのチューニングを行い、実サービスとして提供できるようにしていきます。